
Table of contents
.png)
4 OpenRouter alternatives to prioritize evaluating in 2026
.avif)


As you build AI features in your product, you’ll likely decide to use multiple large language models (LLMs) to manage costs, reliability, and performance.
This requires implementing intelligent routing logic across these models, which will likely lead you to consider a solution like OpenRouter.
Before deciding to move forward with OpenRouter, you should evaluate it alongside its top alternatives: Merge Gateway, Portkey, and LiteLLM.
We’ll help you do just that in this article.
Merge Gateway
Merge Gateway is the control plane for production AI. It gives you unified model access, intelligent routing, cost controls, and full observability in a single system.

Top features
- Routing and fallback logic: This keeps requests reliable when a provider or model is degraded or down. You can specify the exact models you want to prioritize or let Merge determine your routing logic

- Spend policies: You can set spend limits for a feature, team, or customer tier to better control costs
- Unified observability: You can access fully-searchable logs with context on when requests occurred, how many tokens they consumed, the model that was used, etc. This enables your team to trace and debug any potential issues
- Consolidated billing: You can easily track how much you’re spending across LLM providers, what your current spend looks like in a given month, and more to quickly determine any trends and potential issues
- You want to build your own router (BYOR). Define your routing logic as a config by weighting the benchmarks that matter to you, including your own eval scores, and Gateway automatically routes each request to the best model by your definition, with an explanation for every decision
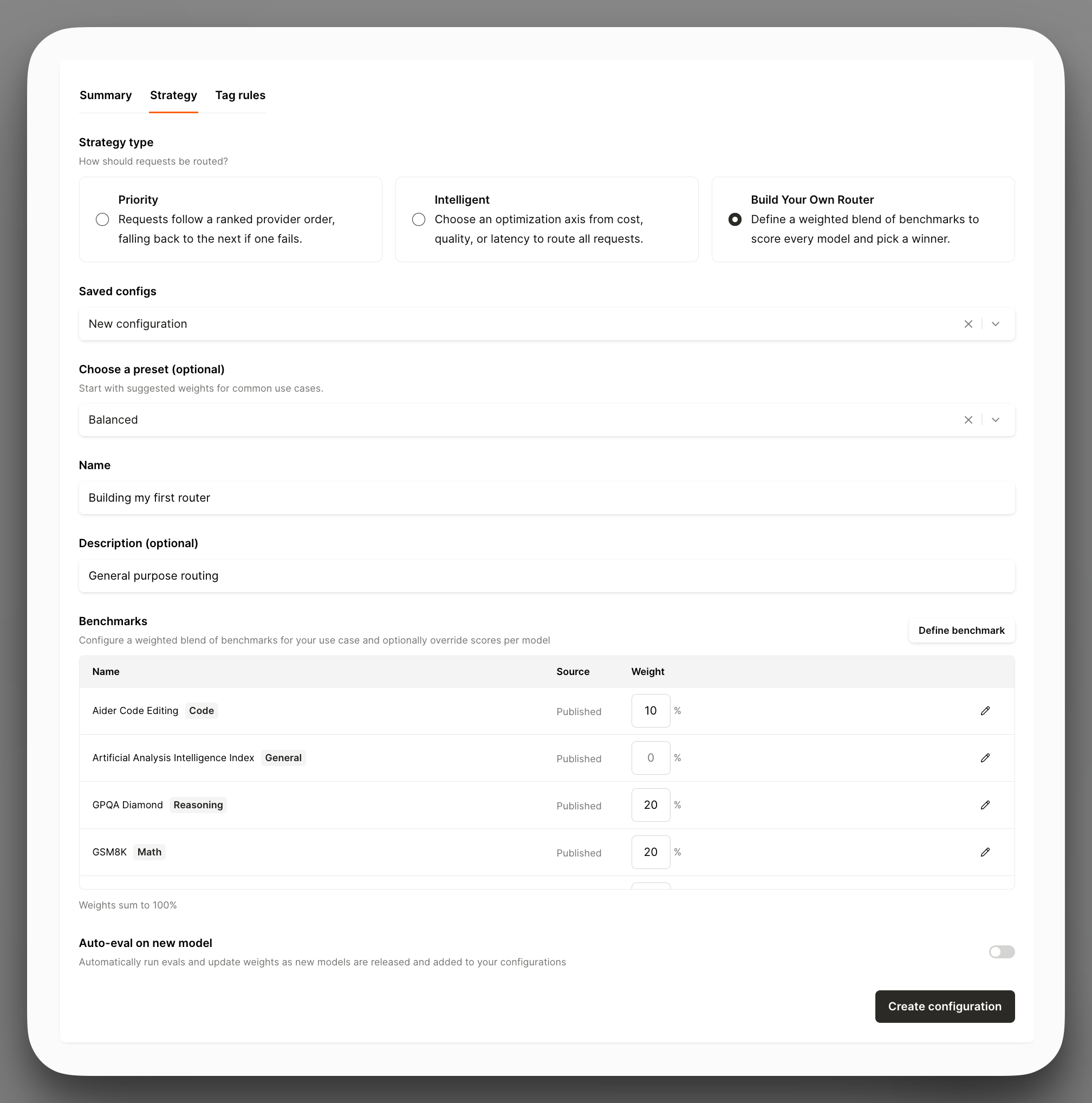
When to choose Merge Gateway over OpenRouter
At a high level, OpenRouter is built for multi-model access and routing. Merge Gateway supports routing too, but adds a production control plane to manage, optimize, and govern LLM traffic as usage scales (budgets, observability, and policy/audit controls).
Here’s a closer look at when you should use Merge Gateway instead of OpenRouter:
- You need enterprise-grade controls: Beyond routing logic, Gateway adds centralized governance, audit-ready logs, and security guardrails in the request path, allowing your team to consistently enforce policies and stay audit-ready as usage scales
- You’d like to implement fine-grained cost controls. Merge Gateway lets you cap spend and explain the factors driving it without building a bespoke setup around each provider
- You’re looking to consolidate billing across LLM providers. Merge Gateway provides a single invoice across model providers, which simplifies billing and spend analysis
{{this-blog-only-cta}}
LiteLLM
LiteLLM is an OpenAI-compatible proxy you run (self-hosted or managed), which sits between your app and multiple LLM providers. It normalizes requests/responses so you can swap providers/models without changing most application code.
Top features
- OpenAI-compatible API surface: Reuse existing OpenAI clients by changing the base URL and API key. This helps minimize integration effort and costly rewrites when switching providers
- Multi-provider routing: Send traffic to different model providers behind one endpoint. This enables you to shift traffic when a provider degrades, gets rate-limited, or becomes too expensive for a given workload
- Self-hosting for control: Run the gateway in your own environment for governance/compliance needs. This helps you meet stricter security and data-handling requirements, and gives you more control over logging, access, and infrastructure-level policies
When to choose LiteLLM over OpenRouter
Pick LiteLLM over OpenRouter when you’re ready to treat the “LLM gateway” as your infrastructure layer, not a hosted aggregator.
Here are more specific reasons:
- You need maximum control and customization (e.g., routing logic). In other words, you want to own the gateway layer so you can manage provider and model selection on your terms
- You have strict compliance and data-handling requirements. For example, you may need to keep prompts and outputs within your own network boundaries, meet specific audit/log retention rules, or ensure only approved providers are reachable from production
- You want to reduce aggregator dependency/vendor lock-in once usage scales. This lets you avoid being tied to a single aggregator’s availability, rate limits, and fee structure as volume grows
Related: The top alternatives to LiteLLM
Portkey
Portkey is an AI gateway layer that sits between your application and LLM providers, giving you a single integration point while you bring your own provider API keys.
It centralizes LLM routing and operational controls (like budgets and rate limits) without acting as the billing aggregator for the underlying model usage.
Top features
- Built-in observability: Access real-time logs and traces, along with spend and performance analytics. This makes it much faster to debug production issues and understand exactly what’s driving latency and cost, without stitching together separate monitoring tools
- Governance and cost controls: Leverage rate limiting and budget/quota enforcement at the API key or project level to prevent runaway spend and abuse proactively. All the while, you can keep different teams or environments within clear usage boundaries
- Broad provider support: You’ll get access to models across providers like OpenAI, Anthropic, Azure, Bedrock, etc., including hybrid/private endpoints. As a result, you can avoid being locked into one provider and choose the best model for each workload, including routing sensitive traffic to private endpoints when needed
Related: The top alternatives to Portkey
When to use Portkey over OpenRouter
Use Portkey over OpenRouter when you want the gateway layer to come with first-class operational controls (e.g., deep tracing/logs) and enterprise governance (e.g., VPC/on-prem deployment), while still using a BYO-keys setup where you pay model providers directly.
Here’s a closer look at scenarios that can lead you to pick Portkey:
- You want a gateway with stronger “ops and governance” primitives. In other words, budgets, rate limits, and traces are first-class features, and you still want to pay providers directly (BYO keys). This lets you reduce your blast radius from abuse and debug issues quickly without giving up direct control of provider accounts
- You care about deep observability and tracing. Rather than adding separate tooling to get production-grade logs and diagnostics, you can bake that in at the gateway layer. This shortens your incident response time and makes it easier to pinpoint whether problems come from prompts, models, providers, or your own application code
- You need more enterprise controls. This includes role-based access controls, audit logs, and custom deployment options (e.g., on-prem style setups). This helps you meet security and compliance requirements while scaling usage across teams without losing visibility or control
TrueFoundry
TrueFoundry is an enterprise AI platform that bundles two things most companies buy separately: infrastructure for hosting and running AI models in production, and an LLM gateway for routing and governing requests across models.

Top features:
- End-to-end AI platform: You’ll get a product for running AI workloads with an AI Gateway; this helps you avoid using separate vendors for both
- Enterprise deployment: You’ll have enterprise deployment options, including in-your-cloud, VPC, on-prem, and air-gapped setups. This helps you maintain data sovereignty and keep data within the customer’s domain
- Governance, observability, and cost visibility: Get RBAC-style access controls, audit logs, and tracing/telemetry for LLM requests, plus spend visibility by team/user/metadata and cost controls like budgets and quotas
When to use TrueFoundry over OpenRouter
Use TrueFoundry when you need a full enterprise AI platform beyond just LLM routing, with stronger deployment flexibility and support guarantees.
Here’s more on when you should leverage TrueFoundry instead of OpenRouter:
- You want an integrated platform beyond routing. If you’re looking for one place to deploy and operate services, jobs, and models alongside an AI Gateway (and not just a standalone LLM routing layer)
- You need the gateway to run inside your environment. If the gateway has to be deployed in your VPC, on-prem, or air-gapped to meet data residency/sovereignty requirements (OpenRouter forces you to use their managed infrastructure)
- You’re looking for strong support. TrueFoundry offers a support SLA on every paid plan, while OpenRouter only offers one on their enterprise plan
{{this-blog-only-cta}}
.jpg)
.png)


